Simple design of an application:
- persisting an uploaded document in an object-storage,
- saving metadata to a database,
- and indexing the document via a dedicated search-engine:
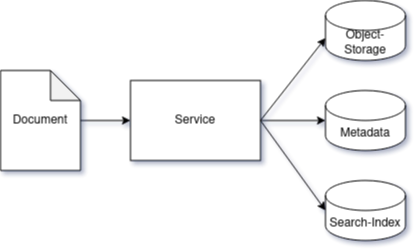
After an upload request succeeded the search-index can be queried and relevant documents can be viewed/downloaded.
And if something goes wrong?
As described by Martin Kleppmann in Designing Data-Intensive Applications, every component of a system can be expected to fail at any time (in particular when connected via network).
Thus, while the design shown above is simple, it may suffer from a couple of issues related to:
- Availability: In the design shown above, all three data sinks need to be available to successfully process a document upload. If either one of them is (temporarily) unavailable, the request fails. Additionally, the expensive indexing operation may become a bottleneck when processing concurrent requests.
- Consistency: Furthermore, only some of the three storage requests may actually succeed while others may fail. No matter how the three storage requests are ordered, a failure may leave the system in an inconsistent state, e.g. being able to find a document when searching via the index, but not when looking for the data in the object-storage (or vice-versa). (Dual-write issues.)
Since the indexing is just relying on data which is also saved to the other stores, it could be postponed so that an upload request can succeed without requiring the search index to be available. In the following design, a message-queue is used to buffer indexing requests for asynchronous processing:
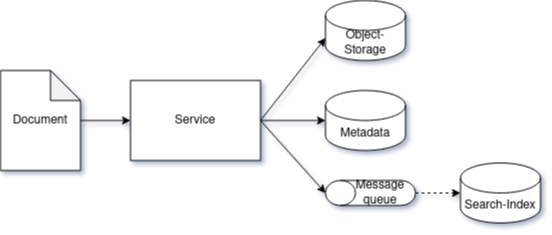
This may improve performance characteristics, since the indexing can limit the number of concurrently executed tasks by limiting the number of concurrently processed messages. Furthermore, the asnychronous processing of an indexing request can be automatically retried in case of temporary failures until it is successfully completed.
However, upload requests will now succeed without the document actually being ready to be searched, which may be perceived as a kind of (temporary) inconsistency.
Another problem: this still requires the message-queue to be available at upload-time and may suffer the same inconsistency issues as described above, since sending a message to the queue may also succeed or fail independently of the other storage requests.
Keeping resources in sync
One way to avoid having only some of the requests succeed is to let all resources participate in the same global, distributed transaction, using the 2-phase-commit protocol.
While this is a common approach, it may not be supported by all resources, and it carries some complexity as it may entail manual recovery procedures (such as “system manager intervention” in case of deviating heuristic decisions after communication breakdowns).
Another way to avoid dual-write inconsistencies without resorting to 2-phase-commit is to persist the requirement of updating other resources as part of a local transaction, e.g. by using the transactional-outbox pattern.
In the following design, the indexing requirement is saved as part of the metadata storage transaction into an outbox table, which is monitored by a message relay component then creating messages for later processing to update the search-index:
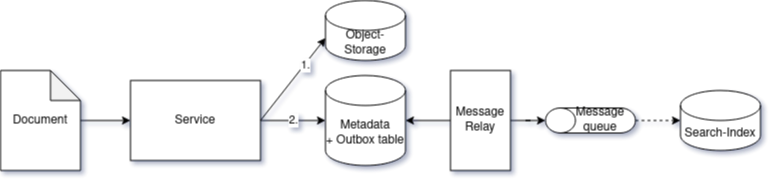
This way, it is ensured that indexing messages are only created in case the transaction spanning the outbox-table-insert successfully committed.
Given a relay component that can asynchonously monitor the outbox table, there is also no need for the relay component or the message-queue to be available at upload-time to let a document upload request succeed.
Nevertheless, one dual-write remains in the system: during the initial processing of the upload request, the document is first stored in the object-storage, and the metadata is then stored together with the indexing request inside the database. In case the object-storage successfully completes the request but the database insertions fail, an orphan document will remain in the object-storage. This problem still needs to be mitigated, e.g. by periodically checking the object-storage for orphan documents which have no persisted metadata.
Another thing which needs to be taken into account is the possibility of failures during the processing of outbox entries and messages, since:
- the relay component needs both to successfully create a message and to acknowledge the processing of the outbox entry
- the message both needs to be processed successfully and the successfull processing needs to be acknowledged
Depending on whether the acknowledgements are done after or before the processing, this results in at-least-once or at-most-once processing.
Choosing at-least-once to make sure that no documents remain non-indexed, repeated processing of indexing messages can occur.
In this case, that should not be a problem since the processing may be made idempotent by first querying the index to check for already indexed documents, or the indexing could just be executed again since it is idempotent already.
CDC with Debezium and the transactional-outbox pattern
To implement the message relay component, microservices.io lists two options: polling the outbox table for events to be published as well as tailing the transaction log. The latter option is described as “relatively obscure although becoming increasingly common”, which is where Debezium comes into play, allowing for a convenient setup of the log-tailing approach.
Debezium is a platform for change data capture, which is able to reliably capture data changes from a variety of sources (e.g. popular relational databases), and to emit these changes as an event stream via a variety of messaging infrastructures.
In the sample app, PostgreSQL is used for saving metadata on uploaded documents (and for the outbox table), Minio, an S3-compatible object-storage for the documents themselves, and OpenSearch for indexing and searching (an open-source fork of Elasticsearch). Redpanda is used as an Apache Kafka-like message broker, and Quarkus for implementing the backend of the user-facing application.
All required components can be setup locally using docker and docker-compose. Just clone the repository from Github and run the following commands from within the directory:
# start needed services:
# (postgres, minio, opensearch, kafka, debezium)
docker-compose up
# run the app, listening at http://localhost:8085
# (will first build the app in a separate build container)
docker-compose -f docker-compose.app.yml
To point it to a running Kafka instance, the Debezium Docker container is supplied an environment variable:
debezium:
image: debezium/connect
depends_on:
- kafka
environment:
BOOTSTRAP_SERVERS: "kafka:9092"
And for setting up Debezium to tail the transaction log of a specific table in a Postgres database, one request is needed:
curl --request POST \
--url http://localhost:8083/connectors \
--header 'Content-Type: application/json' \
--data '{
"name": "upload-service-outbox-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"plugin.name": "pgoutput",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"table.include.list": "public.outboxevent",
"topic.prefix": "upload-service-outbox",
"transforms": "outbox",
"transforms.outbox.type": "io.debezium.transforms.outbox.EventRouter",
"topic.creation.default.partitions": "2",
"topic.creation.default.replication.factor": "1"
}
}'
Publishing and consuming messages with Quarkus
For simple setup during development, the request shown above may also be issued automatically during Quarkus startup, e.g. using a microprofile RestClient:
@IfBuildProfile("dev")
@ApplicationScoped
public class SetupDebeziumOnStartup {
@Inject
@RestClient
DebeziumSetupService service;
public void onStart(@Observes StartupEvent ev) throws Exception {
try {
service.setupConnector(getBody());
} catch (ConflictException e) {
// ok, already setup
}
}
@IfBuildProfile("dev")
@ApplicationScoped
@RegisterRestClient(baseUri = "http://debezium:8083") // configurable
@RegisterProvider(ConflictDetectingResponseMapper.class)
public static interface DebeziumSetupService {
@POST
@Path("/connectors")
@Consumes(MediaType.APPLICATION_JSON)
void setupConnector(JsonObject body);
}
}
Having this configuration in place, the Quarkus app can then start to write to the outbox table, which can be further simplified by including the corresponding Quarkus extension as a Gradle dependency:
implementation 'io.debezium:debezium-quarkus-outbox'
This allows to write to the outbox table by simply firing a sub-classed ExportedEvent:
@Inject
Event<IndexingRequiredEvent> outbox;
@Transactional(value = TxType.MANDATORY)
public void indexAsync(DocEntity doc) {
IndexingRequiredEvent event = new IndexingRequiredEvent(doc.getFilename(), doc.getFilename(),
Instant.now());
outbox.fire(event);
}
If configured, the Quarkus extension will also take care of immediately deleting entries from the outbox table to prevent it from growing over time.
Debezium will then start to capture the data changes and publish corresponding messages to the configured Kafka topic.
Reading messages from a Kafka topic with Quarkus is also straightforward as described in the corresponding guide, using Smallrye Reactive Messaging:
@Incoming("indexing-events") // configured to map to a specific Kafka topic
@Blocking(ordered = false) // messages only affect distinct documents, so ordering is expendable
public void receive(String message) {
String payload = getPayload(message);
indexingProcessor.processIndexingRequest(payload);
}
The message processing should be extended by automatically retrying message processing in case of transient failures (e.g. caused by unavailable upstream services), as well as by eventually handling persistent problems, e.g. in a way described in this article (e.g. the Robinhood approach which allows for the simple implementation of a dedicated UI for flexibly triggering a reprocessing of messages e.g. after bugfixes have been deployed).
When processing an indexing request message, the document to be indexed is first downloaded from the Minio object-storage using the Quarkus Minio extension which provides convenient access to the Minio Java API.
Subsequently, an indexing request is send to OpenSearch using the low-level RestClient. To be able to index PDF-documents, a special ingest-plugin for attachment processing needs to be installed:
# custom OpenSearch Dockerfile to install the ingest-attachment plugin
FROM opensearchproject/opensearch:2
RUN /usr/share/opensearch/bin/opensearch-plugin install --batch ingest-attachment
Further OpenSearch configuration is automatically done on app startup via the RestClient.
Result
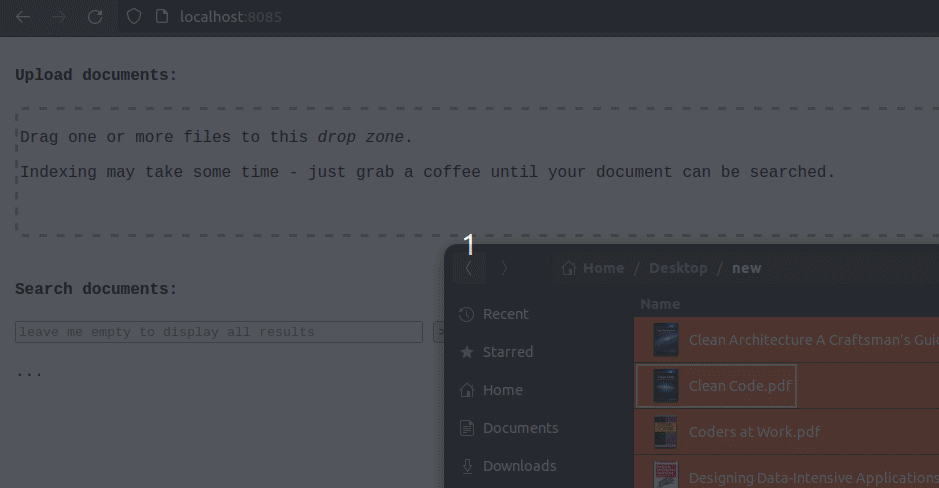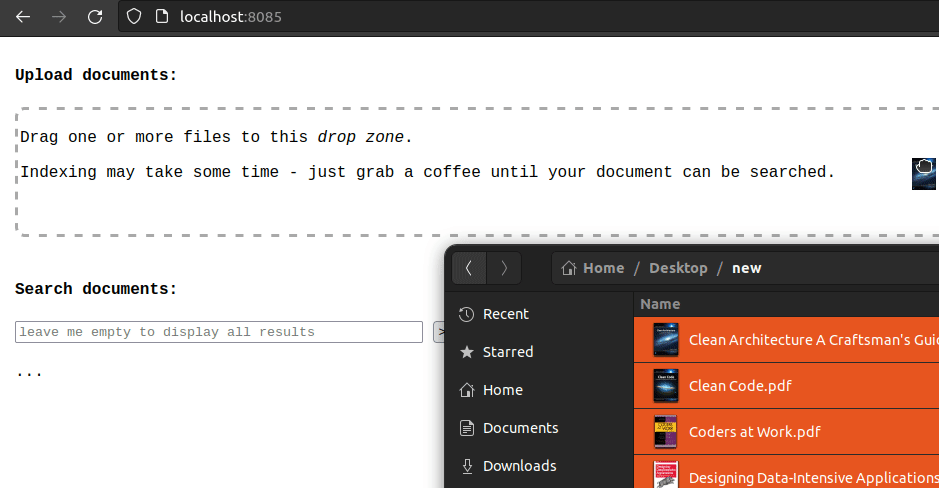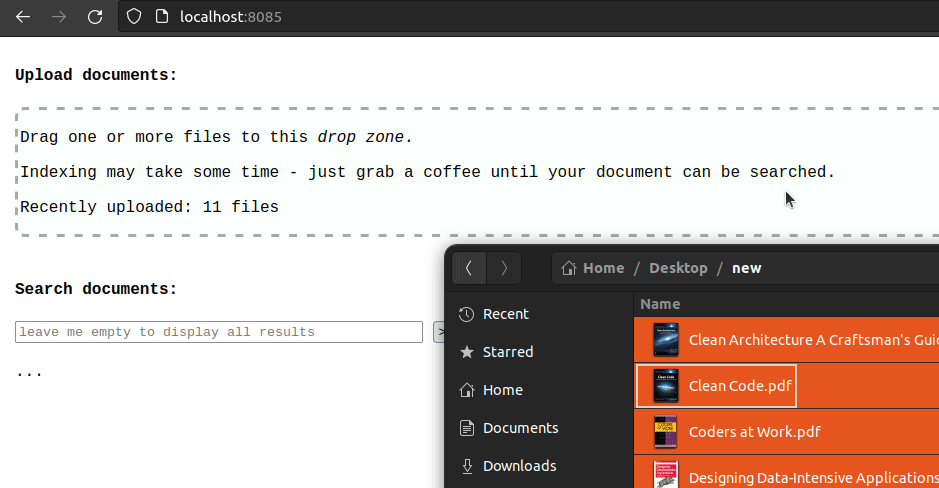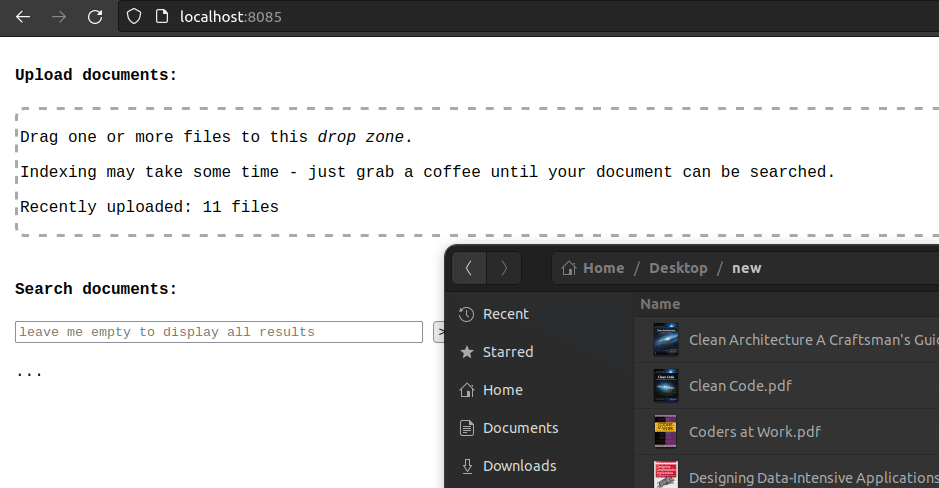
The following screenshots show how uploading and searching documents looks like and how the data processing proceeds:
PDFs can be uploaded by dropping them onto the page:
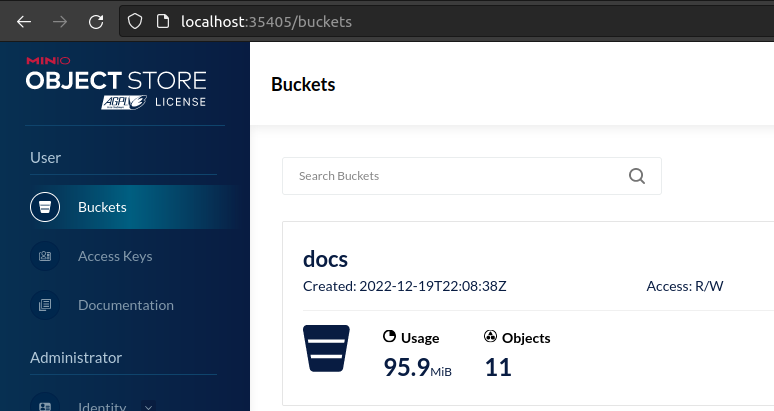
Files are uploaded to Minio, as shown by the built-in UI:
Upload-requests complete successfully, however no documents have been indexed yet:
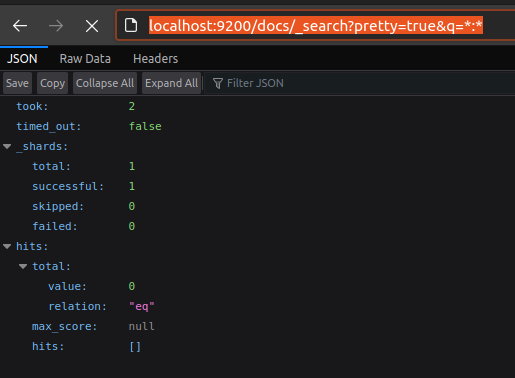
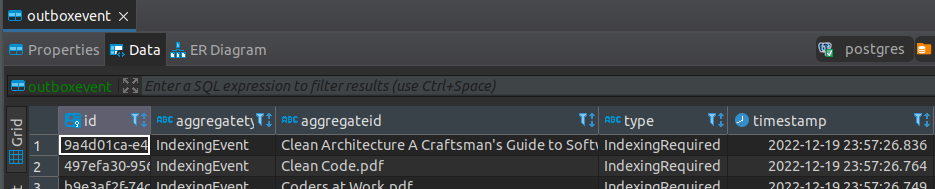
Metadata was saved to Postgres, together with the outbox table entries (automatic deletion disabled):
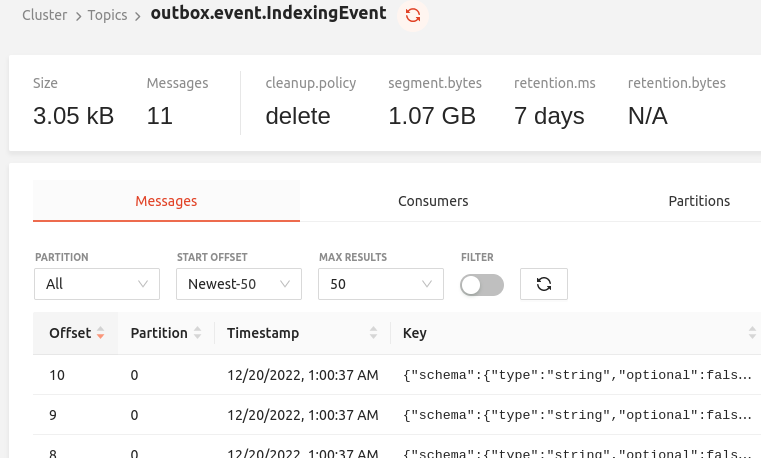
Debezium captures the inserts and creates corresponding Kafka messages, which can be inspected e.g. using the Redpanda Console:
The app then processes the messages and indexes the documents, which can then be queried. Results also include highlights showing the context in which search terms occured, and the document can be viewed: